Are you Polish? FSharp will tell us, probably - part 1
Forenotes from 2023
This post was originally published on my blog on March 11th, 2017 and was the 2nd big entry of my Daj Się Poznać 2017 blog post series 🖋️. Back then I was primarily a C# developer and I had been reading a lot about this other, less known .NET language called F#. The language, and the way it forced me to relearn how I think about programming, quickly had me fascinated. It seemed like sharing my findings about F# with others would be a great way to get more proficient with it, and perhaps spread around my newly found enthusiasm :). A few years later, I can definitely say that F# had a deep influence on my career. Let's dive into it 🙂.
Are you Polish? F# will tell us, probably - part 1
In my previous post I created a small Hello, World! web application using WebSharper. As F# is predominant in WebSharper, I figured I'd write a few posts about the language itself. I didn't want to write yet another F# tutorial focused on theory (there are plenty of those out in the Wild), so I came up with a simple use case I could use as material for those posts. How about we wrote a small script that would tell the probability a given surname is Polish?

This would serve as:
- a smooth and practical introduction to F# for those who don't know it yet, with just a pinch of functional programming theory (nothing too complicated, I promise).
- a short refresher for the others (myself included).
- a unique opportunity to learn a little more about Polish surnames!
Let's start then. First, let's describe the problem at hand and what we want to achieve. Given an arbitrary surname, we want to know if it is either:
- Definitely Polish
- Probably Polish
- Not Polish
The magical algorithm
In order to do so, I came up with a rather naive algorithm that would help us get the desired results. This algorithm is based on 3 rules:
- How many exclusive Polish letters does the surname contain? The Polish language has a set of of 9 letters based on the Latin alphabet, but combined with diacritics. Here is the complete list: ą, ć, ę, ł, ń, ó,'ś, ż, ź
- How many Polish digraphs does the surname contain? Put simply, a digraph is a pair of letters that, combined together, form a new letter with a sound on its own. The Polish language contains 7 digraphs: ch, cz, dz, dż, dź, rz, sz
- Does the surname end with a common Polish ending? After analysing a few dozens of popular Polish surnames, I put together a list of the most common endings: wicz, czyk, wski, wska, ński, ńska, ski, ska, cki, cka, ło, ła, ak, rz You will notice that some of them are quite similar, like wski / wska or cki / cka. The forms ending by i usually mean the bearer is a man while the ones ending by a mean the bearer is a woman. Easy!
The algorithm would be a bit too minimalist if we stopped here, so I decided to introduce the concept of points to it:
- Each Polish letter will earn the surname 1 point.
- Each Polish digraph will earn the surname 3 points.
- A Polish ending will earn the surname 6 points!
And last but not least, by dividing the total of points by the number of letter in the surname, we would obtain its Polish density, which in turn would give us our final answer:
- Any density below 0.2 would yield Not Polish.
- Any density between 0.2 and 0.8 would yield Probably Polish.
- Any density above 0.8 would yield Definitely Polish.
Let's apply this to a sample surname: Młynarz
- it would earn 10 points (1 for the ł letter, 3 for the he rz digraph, and 6 for the rz ending!)
- the density would be 10 points divided by 7 letters = 1.43
- the expected end result would be: Definitely Polish
Voilà! As you're probably blown away by the complexity of the algorithm, let's take a minute to catch our breath.
The magical code
Without further ceremony, let's go over the code that you can find on this public gist. Here are a few figures about it. The single file contains:
- 167 lines in total
- of which 60 are either blank lines or comments (35.9%).
- of which 39 are evaluations or tests (23.4%).
- of which 68 are actual logic (40.7%).
- 3 declarations containing the Polish letters, digraphs and endings described above.
- The whooping total of 16 function definitions! That's an average of 4 lines per function.
The file is an F# script (with the .fsx extension), which means you can run it dynamically within the F# Interactive console, by highlighting part of the code, right-clicking and choosing the Execute in Interactive option within Visual Studio:
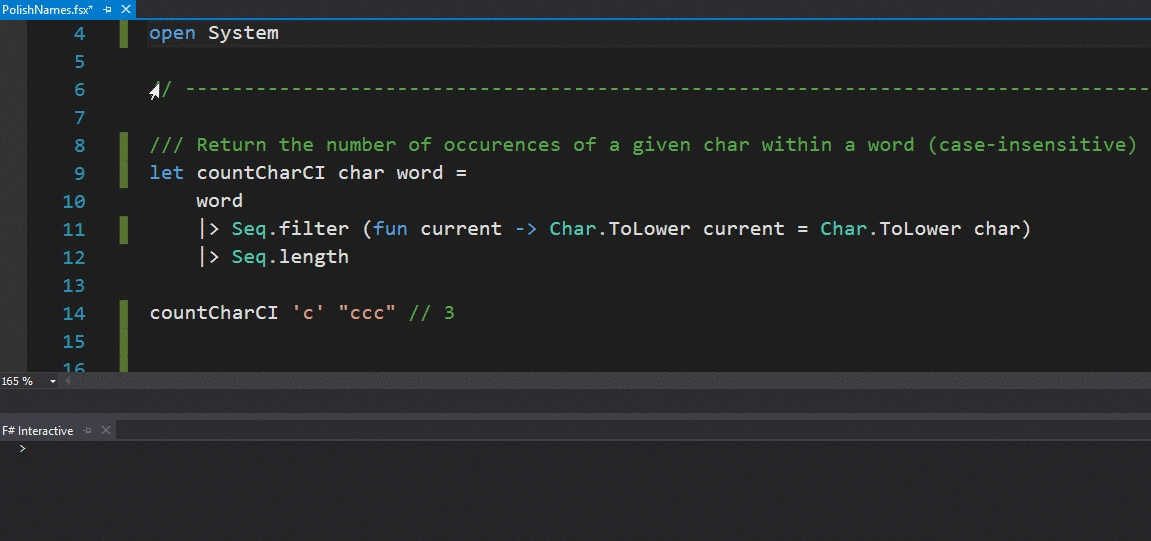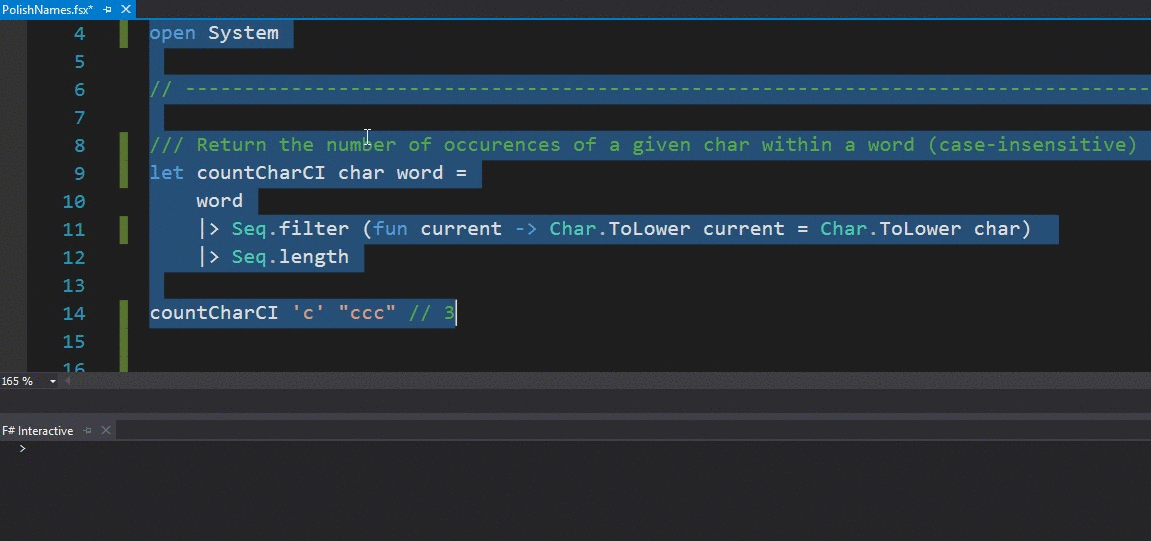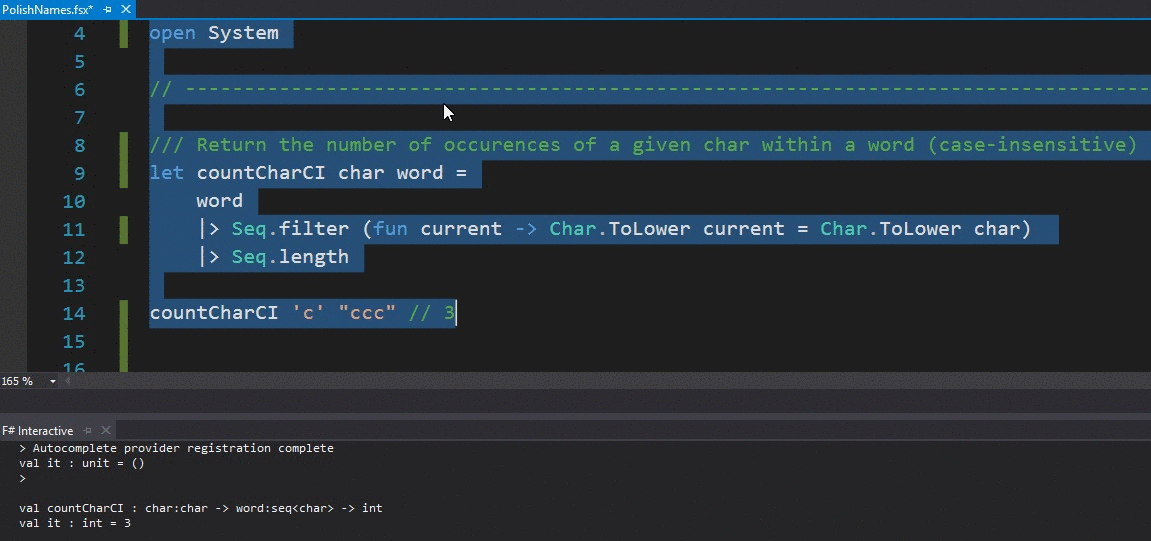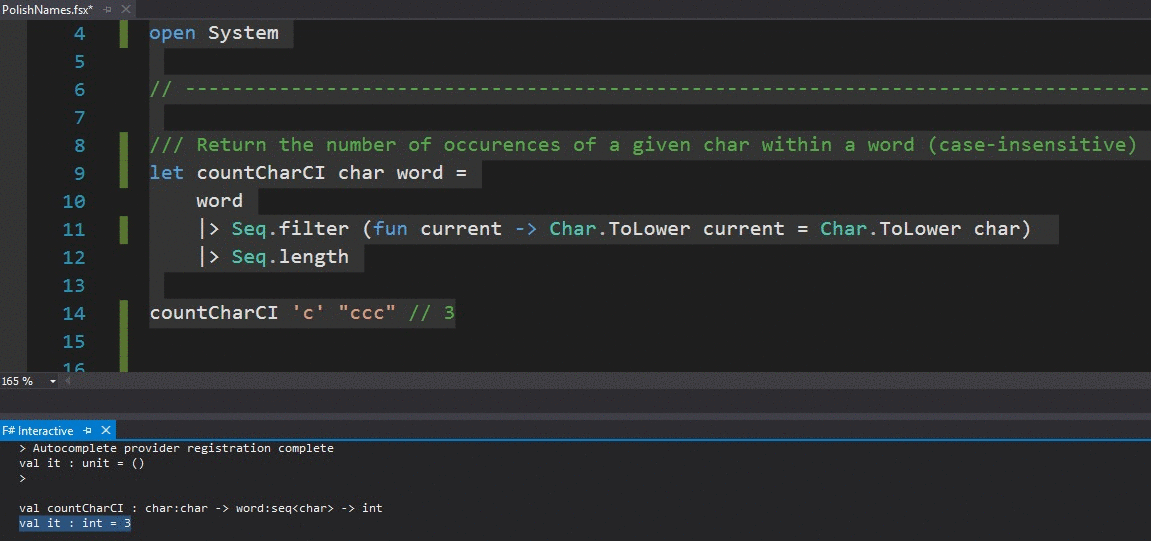
This is a wonderful feature that allows for very fast development cycles: you write a new function, test it as you go and copy it over to your production code once you are pleased with the results.
Let's have a look at the very first function of the script, countCharCI. The function returns the number of occurrences of a character within a given word, and it obviously takes 2 parameters as input: char and word.
/// Return the number of occurrences of a given char within a word (case-insensitive)
let countCharCI char word =
word
|> Seq.filter (fun current -> Char.ToLower current = Char.ToLower char)
|> Seq.length
Y'all get any more of them types?
I hear you say already:
"But Jimmy, isn't F# supposed to be a strongly-typed language? Can't see any of those type declarations in here."
Thanks for asking. This is because the F# compiler features a powerful type inference system and is able to guess the type of your parameters from their usage (most of the time). Even if you don't directly see them in the code, the types are really there though and will be enforced by the compiler and run-time. This prevents a lot of funky issues you could get with weakly-typed languages (Yes JavaScript, I am looking at you!). You can check this by hovering over the parameters' names in Visual Studio.
The char parameter is of type char:

The word parameter is of type seq<char> (a sequence of char, which a string is):

And finally the whole function has the following signature:
_char:char -> word:seq<char> -> int

Which basically means that it takes 2 parameters as input (the char and the seq<char>) and returns an int. Perfect! Sometimes though, the F# compiler will need our help figuring out the type of certain parameters. This is for instance the case for our one-liner finishWithCI function at line 92:
/// Check whether a word has the given ending (case-insensitive)
let finishWithCI (suffix:string) (word:string) =
word.ToLower().EndsWith(suffix.ToLower())
Here we need to explicitly state the type of both suffix and word parameters in order to use the ToLower and EndsWith functions on them. This lets the compiler know that those two functions indeed belong to the string type. There are currently 32 parameters defined in the whole script, but only 5 of them actually are explicitly annotated. I love it!
As this post is getting pretty long (once again!), let's end by going over the logic of countCharCI:
/// Return the number of occurrences of a given char within a word (case-insensitive)
let countCharCI char word =
word
|> Seq.filter (fun current -> Char.ToLower current = Char.ToLower char)
|> Seq.length
The function makes use of the Forward Pipe operator |> twice. This operator is omnipresent in F# and we will dedicated a whole blog post to it soon. Simply put, what it does is pass the value on the left side (word here) as the last parameter of the function on the right side (Seq.filter).
The Seq.filter function applies its 1st parameter, a predicate function, to each element of the sequence passed as its 2nd parameter. In our particular case, it will check if characters contained in word match the reference character passed to countCharCI. It will make the comparison case-insensitive by calling Char.ToLower on each side of the equality operator first:
fun current -> Char.ToLower current = Char.ToLower char
The fun keyword above allows to define a lambda expression, the same way as you would in C#. Please note that C# uses a fat arrow => while while F# uses a slim arrow ->. The Seq.filter itself returns a new sequence of characters that matched the predicate above. This sequence is then piped to Seq.length that simply returns its total length (thus the number of occurrences of char within word).
We're almost there. Let's test our shiny new function with the following evaluations:
countCharCI 'C' "ccc" // returns 3
countCharCI 'c' "cCc" // returns 3
countCharCI 'c' "" // returns 0
countCharCI '2' "145" // returns 0
countCharCI '3' "3f3sdf" // returns 2
It works! Let's call it a day! I will follow up with a second post (Are you Polish? FSharp will tell us, probably - part 2) where we will see the whole script in action, and finally get to answer the crucial question: Is your surname Polish?
More soon, take care!